





Clustering in Relativity
- May 20, 2019
- 2 min read
In Relativity you can use the clustering conceptual analytics tool to create groups of conceptually similar documents without the need to define categories, or select a set of training documents. Relativity will position documents in a conceptual index and then use a naming algorithm to label each node in groups of clusters. Clustering is a good way to get an overview of a new data set.
1. First go to the Documents tab and select the set you want to cluster. A clustering operation can be run on a saved search, a folder, or the complete workspace. Individual documents can be checked off.
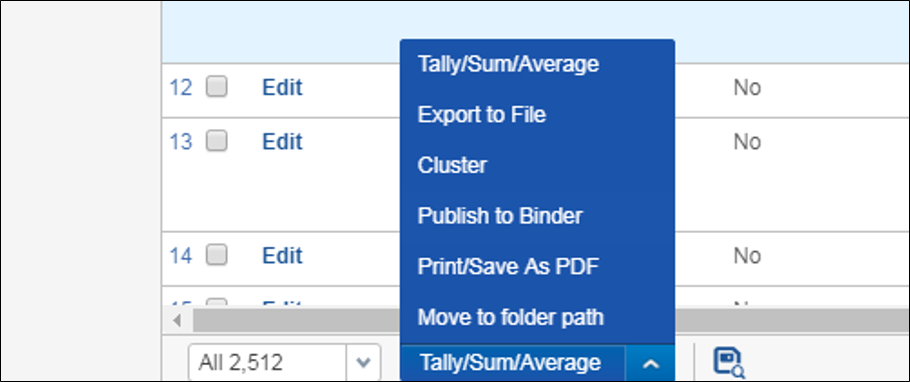
2. Choose 'Cluster' from the mass operations drop down menu at the bottom of the screen.
3. You'll have the option to create a new cluster, or replace an existing cluster. If you choose to create a new cluster, you will be prompted to name the cluster and select an index. The index must have queries enabled, and all of the documents to be cluster must be covered by the index. [Any documents that are not will be put in a cluster named 'Not Clustered'. Documents without any searchable text will be placed in a separate group named, 'UNCLUSTERED'. All documents in the workspace which are not submitted for clustering will be in a cluster named, 'Not set'.]

4. In the Title Format field, select one of the three options:
a. Outline and Title - shows a number, title, document count in the cluster, and a coherence score.
b. Outline Only - number, document count in the cluster, and a coherence score.
c. Title Only - title, document count in the cluster, and a coherence score.
The title will be limited to four words.
5. Maximum Hierarchy Depth - this setting is for the number of cluster levels - between 1 and 5. The default is 3. When this value is greater than one, no more than 16 top level clusters will be created.
6. Minimum Coherence - The lower the coherence value, the more loosely related the documents in a cluster will be. When analytics finds documents below the coherence score, it will create subclusters. The default setting is 0.7.
7. Generality - determines the specificity of clusters at each level. It should be set to a value between 0 and 1, 0.5 being the default. A lower generality value will create 'tighter' and more numerous clusters.
8. The option for 'Create Cluster Score Field' will create a field storing a coherence score for each document. If this option is checked, the operation will take significantly longer to complete.
9. The cluster is created in the browser on the left. Click on the asterisk icon.

The numbers used for each cluster and subcluster show the total number of documents in a cluster (including its subclusters), followed by a second number listing the coherence score. So, in this example we can see that the subcluster '6.1.2 party, letter, collateral, paragraph' has 28 documents with a coherence of .91 - a group of very conceptually similar documents.