Everlaws's document review platform is more intuitive and visually appealing than Relativity, and includes several functions which the more widely used platform lacks.
When setting up a search, you not only have the option to include other family members or near duplicates, but you can also exclude certain documents from the groups added to the search term results. A graphic is included to make clear which documents without keyword hits will be added in the results.

As you select the option to include other versions, attachments, duplicates, or members of the same email thread as the documents which match your search criteria, Everlaw will calculate the percentage of additional documents that will be returned.

There's also an option to exclude duplicate documents from the results.
Everlaw's canonical metadata function will standardize entries in similar metadata fields - so entries of custodian names in fields named, 'Custod'; 'Custodian'; 'Doc Cust' will be merged. Users have the option to toggle between the original metadata and the Everlaw version on the layout in the document viewer.

It is also possible to search on any metadata field in the layout for documents which have the same value:

Everlaw also does a good job of tracking links between documents, indicating the 'backlink' for a document, or another document available in the database which contains a OneDrive or Google Vault link to the current document.

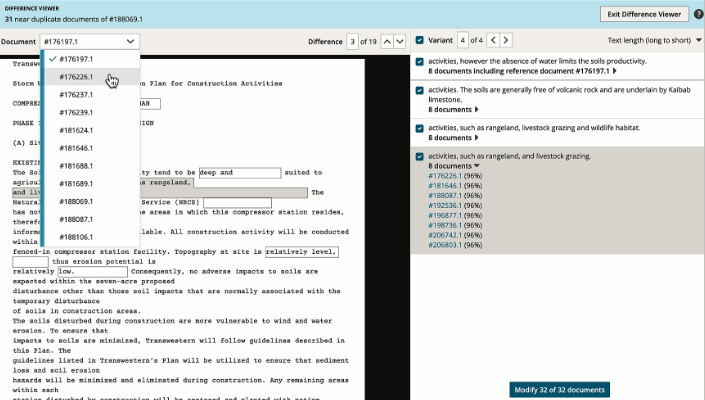
Everlaw's Difference Viewer makes it easy to identify where multiple versions of a single document have been edited. It gives you the ability to scroll through the sections which differ, and then review the variants in the panel to the right.