





The key to getting AI systems like Harvey AI to generate effective drafts of legal briefs, and solve other problems is to devise a good prompt to get AI to give you the result that you need. In the AI for Legal Basics certification course, Harvey emphasizes that its system will not work well if given ambiguous instructions, and that projects should be divided into discrete tasks. A good prompt will indicate what should not be done, and the prompt should specify which authorities should guide it.

As a new addition to its extensive array of electronic discovery training materials, Relativity has prepared a guide, The Legal Professional’s Guide to Prompt Engineering, which can be downloaded here: https://resources.relativity.com/legal-professionals-guide-prompt-engineering-lp.html
The core idea is to alter the language often used in legal documents to phrasing that provides AI with better guidance about what to generate:

Here are some key takeaways:
Having the ability to write well is key. Prompt engineers often have degrees in English, rather than in fields related to technology.

Relativity references OpenAI's tips for engineering effective prompts which include:
Use the latest LLM.
Clearly distinguish between the instructions for what the AI system should do and the information it should be reviewing. OpenAI marks text to be analyzed with 3 quotation marks """:

Be specific about the outcome. Give examples of the results that the system should generate. You want to avoid 'zero-shot prompting', which provides instructions without demonstrating the desired result.

Much like the tried and true EDRM model, Relativity recommends thinking of prompt engineering as an iterative process. It's necessary to interact with the system to refine the result that it produces.
AI can be instructed to indicate its own reasoning. CoT - chain-of-thought prompting is when a prompt tells the system to explain how it is reaching a conclusion. A prompt can, for example ask that the system identify an issue, the relevant rules, and state how the rule applies to the facts, showing how a conclusion is reached.
Use role-based prompting: a prompt can specify that a system answer a question as someone working in a specific position would.
Contextual prompting is when a prompt includes the text cited to for the facts of a case or the relevant law. The content of a contract or a statute is added to the prompt.
AI systems are also guided by system prompts which users can't see that restrict the possible results. They may be prevented from giving answers with a political perspective.
Relativity's aiR for Review is limited to 15,000 characters. Compare this to the much higher token / page limits in Harvey discussed in the March 20, 2026 Tip of the Night.
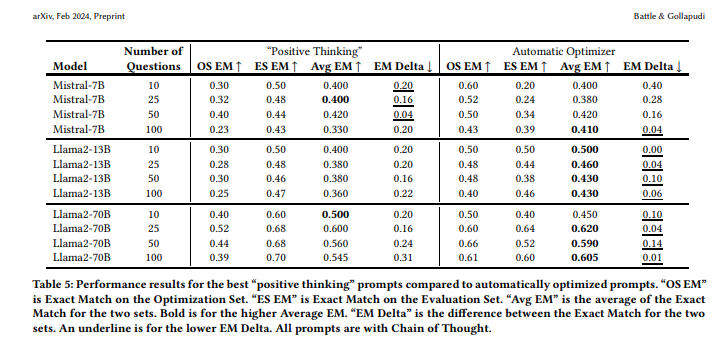
Algorithms should be used to optimize prompts. They cite a research study conducted at VMware, Rick Battle and Teja Gollapudi, The Unreasonable Effectiveness of Eccentric Automatic Prompts, arXiv:2402.10949v2 (2024), which found that optimized prompts will give higher exact matches on average than prompts which merely encourage the system to arrive at a solution.
Relativity has its own prompt optimizer, or kickstarter.

It's possible to upload up to 10 documents (which can't have more than 300K characters), such as complaints, memoranda summarizing a case, or requests for production, to prime this function so that it can autogenerate criteria for a prompt.
The active voice should be used in prompts, and double negatives should always be avoided.
Boolean operators can be used in prompts, and even putting certain phrases in ALL CAPS or adding exclamation points can lead to a better result.
AI systems may get confused by some legal terms which are too vague such as 'reasonable' or 'substantial'.
There is currently some debate as to whether prompts should be regarded as work product, or if they ought to be disclosed in ESI protocols just as search terms are.











