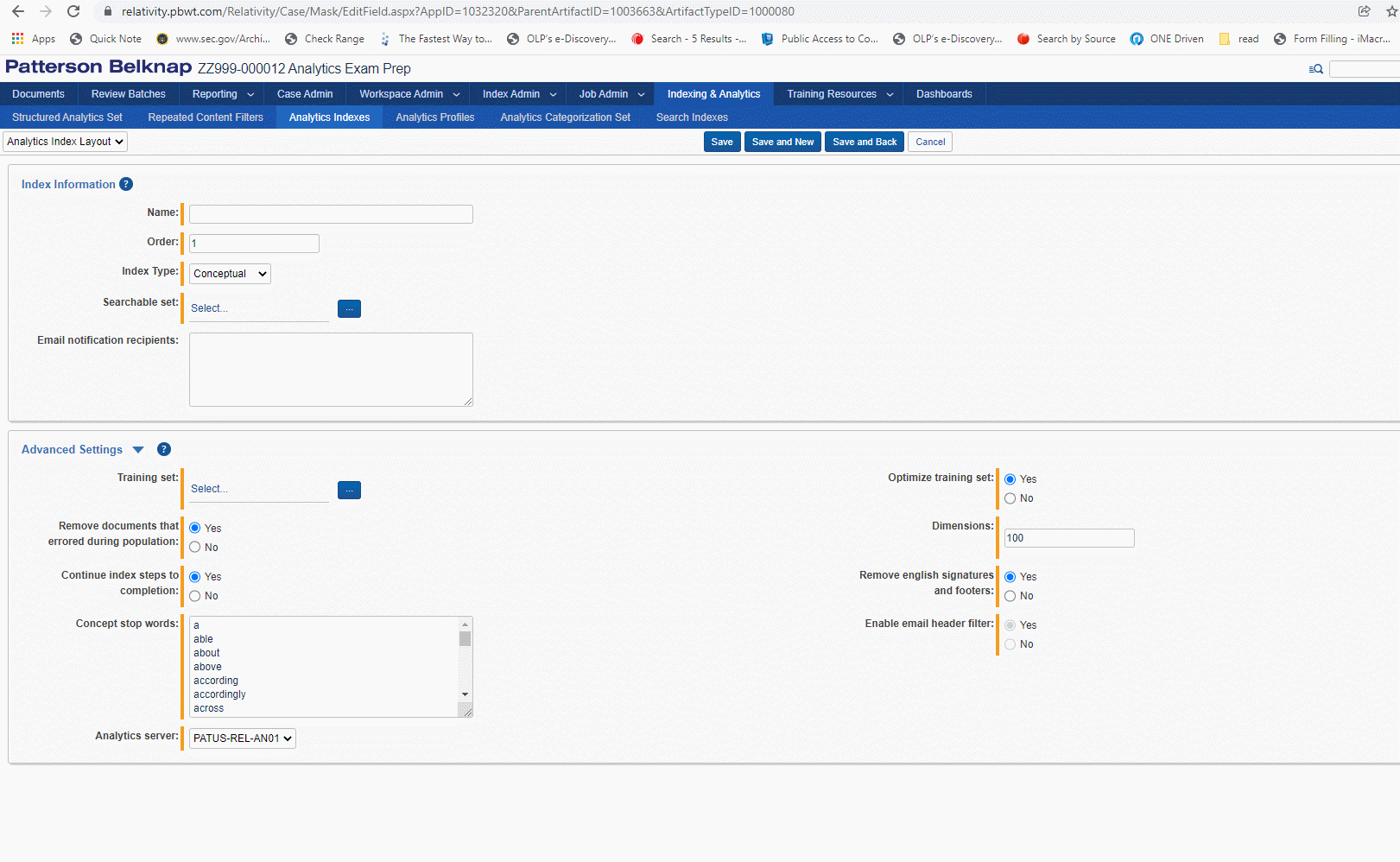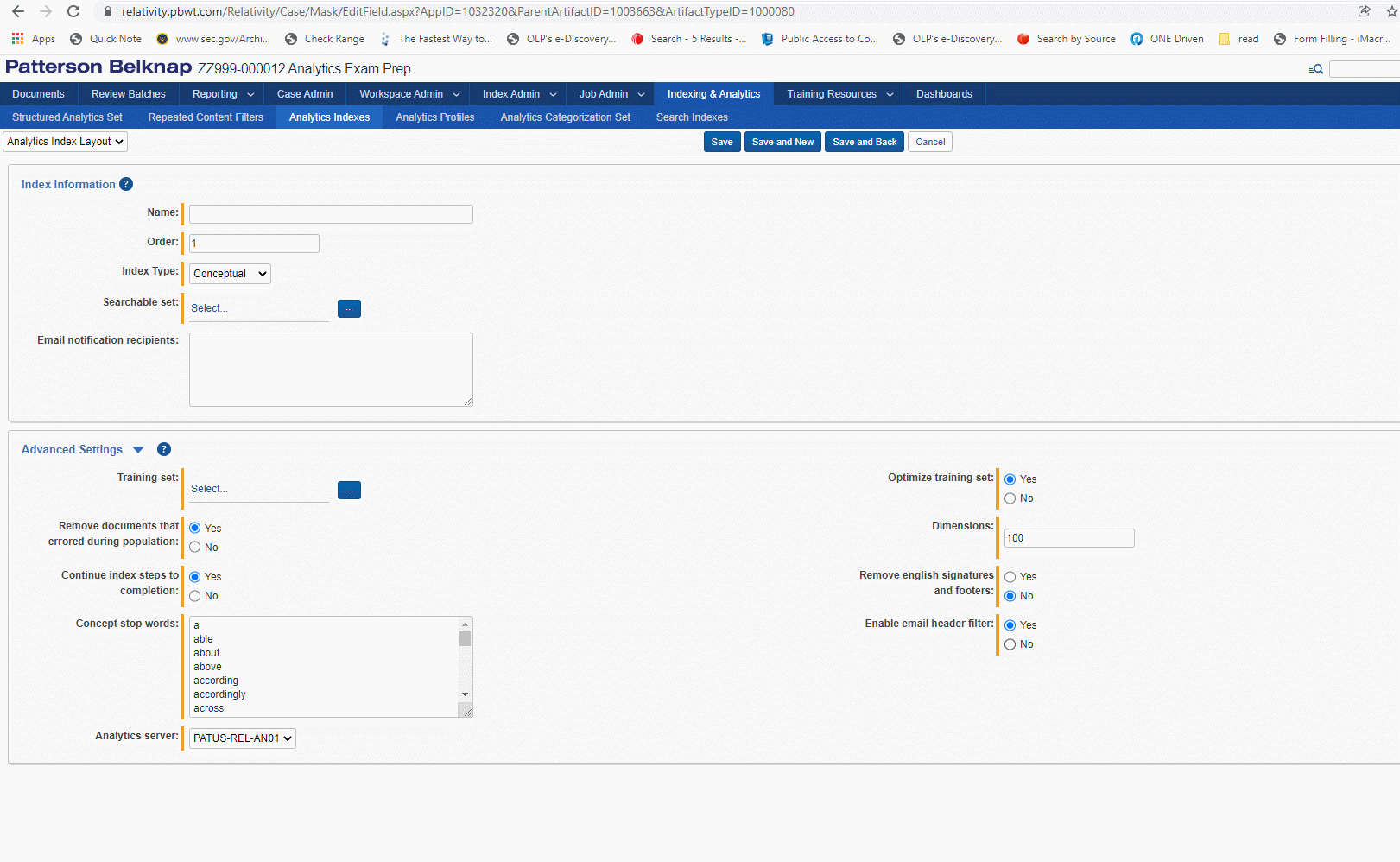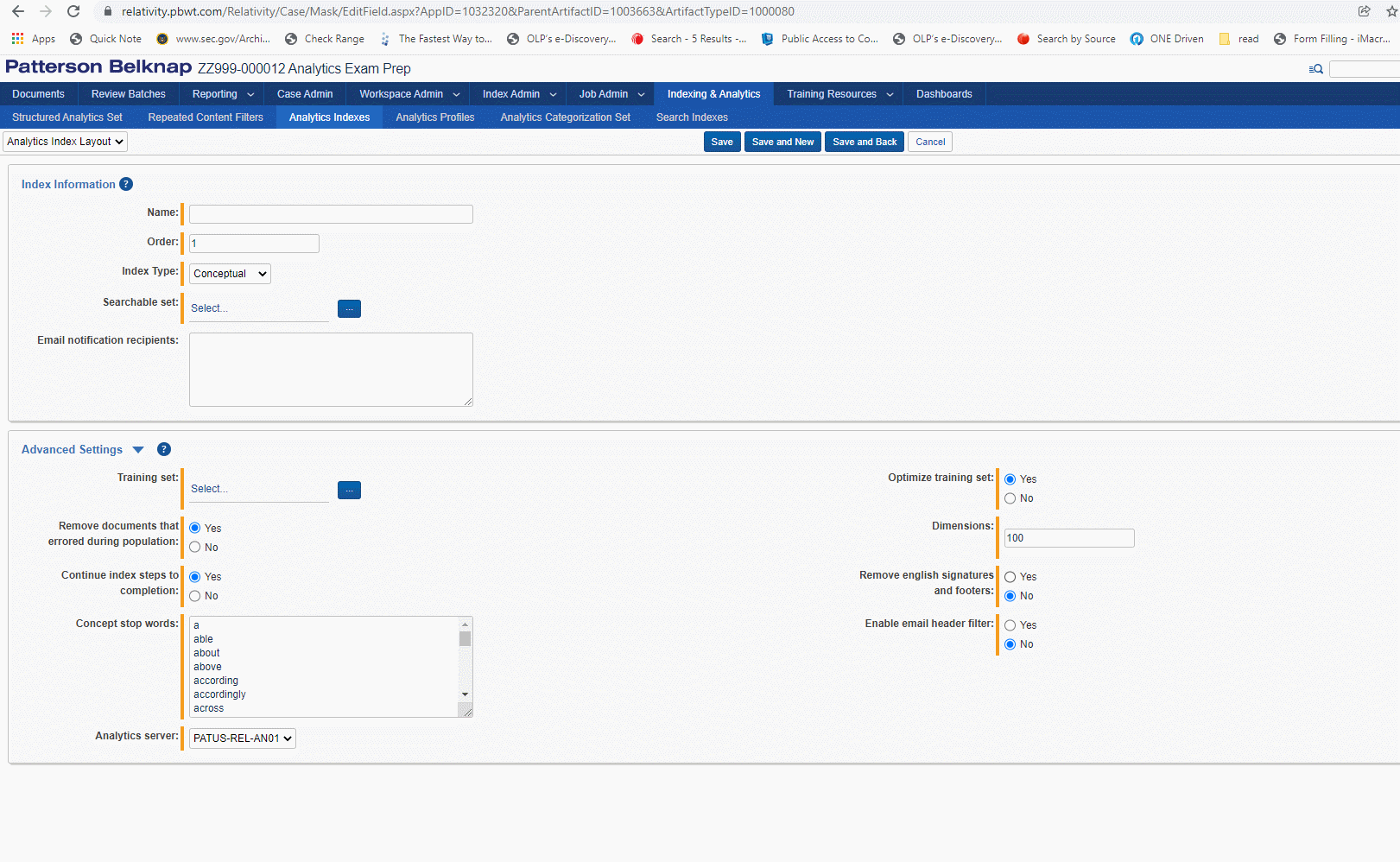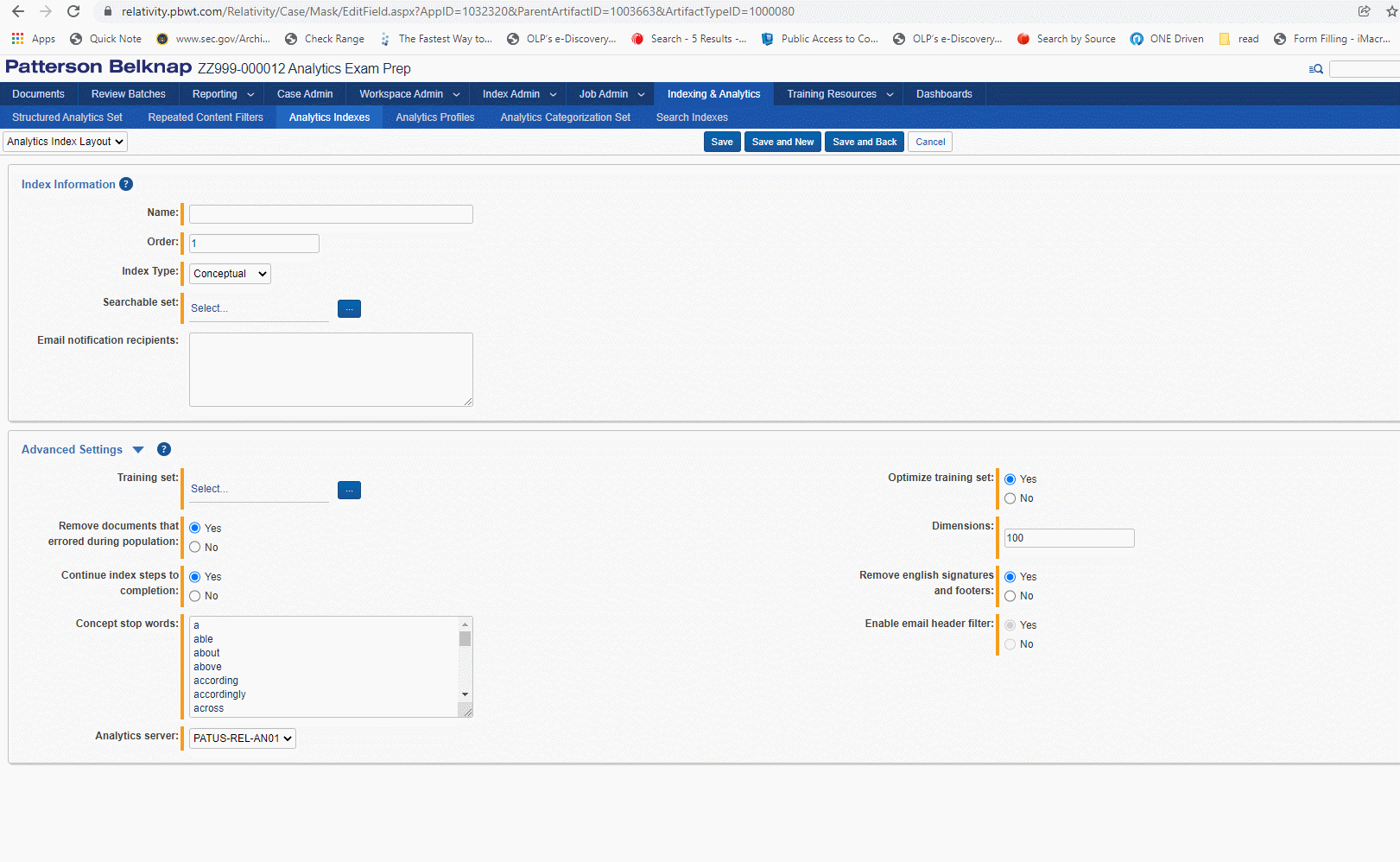
Keep in mind that when you set a regular expression filter for a structured analytics set in Relativity, the regex filter will not be run against the extracted text as you can see it for a document in the Viewer. While the extracted text is displayed with line breaks and whitespace, this text is transformed when it is in the Analytics pipeline. The pipeline text uses the regex \r\n markers [return and newline] in place of line breaks, and will consolidate multiple blank spaces to a single space.
Extracted text may look like this:

. . . but the pipeline text will look like this:

There's just one long string of text in the analytics pipeline. So if you want to search for an email footer reading, "Under the General Data Protection Regulation GDPR 2016 679 we have a legal duty to protect any information we collect from you", accounting for varying GDPR sections, a regex filter for a structured analytics set . . .

. . . should be set like this:

. . . without the additional spaces before and after the relevant GDPR section.
If you want to filter out multiple disclaimers added to email footers, and Bates numbers from more than one party's production, you'll need to craft a single regex search which can account for all these targeted terms. No more than one regex filter can be applied to a structured analytics set.